はじめに
この記事では、Stable Video Diffusion をローカル環境で動作させる方法について解説します。
Stable Video Diffusion は、静止画から動画を生成できる最先端の AI モデルであり、Hugging Face の stable-video-diffusion を利用します。
GPU を活用することで高速に処理を行うことができますが、適切な環境構築が必要です。
本記事では、環境構築の手順からスクリプトの実行まで を詳しく解説していきます!
1. 事前準備
1-1. Hugging Face にログイン
まずは、Hugging Face にログインしましょう。
Hugging Face は、機械学習モデルを簡単に利用できるプラットフォームです。
- Hugging Face の公式サイト にアクセス
- Sign Up または Log In からアカウントにログイン
1-2. トークンを取得(Hugging Face の API トークン)
Hugging Face のモデルを利用するには API トークンが必要です。
- 右上のアイコンをクリック → Settings を選択
- Access Tokens のページに移動
- New token ボタンをクリックし、新しいトークンを作成
- 名前:任意の名前
- 権限(Role):
writeまたはreadで OK
- 生成されたトークンをコピーしておく
このトークンは、後ほど .env ファイルに記載することで使用します。
1-3. CUDA(GPU)対応の PyTorch をインストール
1-3-1. 既存の PyTorch をアンインストール(必要に応じて)
既に PyTorch がインストールされている場合は、一度アンインストールしておきます。
pip uninstall torch torchvision torchaudio1-3-2. CUDA 対応版の PyTorch をインストール
CUDA 対応の PyTorch をインストールするには、PyTorch の公式サイト から 対応するバージョンのインストールコマンド を取得し、実行します。
例えば、CUDA 11.8 を使う場合、以下のコマンドを実行します。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1181-4. Python インタープリタを起動してインストール確認
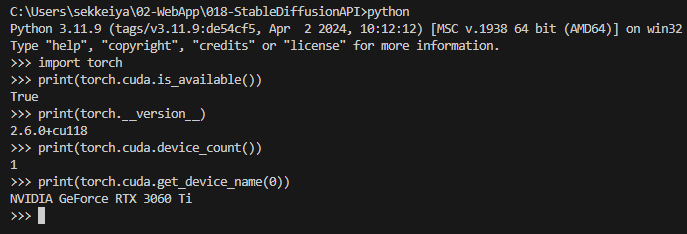
インストールが正常に完了したか確認するために、Python を起動して以下のコマンドを実行します。
pythonimport torch
print(torch.cuda.is_available()) # True が表示されれば成功
print(torch.__version__) # インストールされた PyTorch のバージョンを確認
print(torch.cuda.get_device_name(0)) # 使用可能な GPU の名前を取得True が表示され、NVIDIA GeForce RTX 3060 Ti などの GPU 名が表示されれば、CUDA 対応版が正しくインストールされています!
1-5. Python インタープリタを終了
exit()1-6. もう一度コードを実行して動作確認
PyTorch が GPU を正しく認識していることを確認したら、次のステップへ進みます。
2. 実装
2-1. ディレクトリを作成
Stable Video Diffusion のためのディレクトリを作成します。
mkdir stable-video-diffusion
cd stable-video-diffusion2-2. 画像を生成・配置
stablediffusionを使って画像を生成しました。⇒https://huggingface.co/spaces/stabilityai/stable-diffusion
ファイル名は「input.jpg」とします。

動画の元となる画像を配置します。
input.jpg という画像を input/ フォルダに置きます。
mkdir input
mv ~/Downloads/input.jpg input/2-3. 依存関係をインストール
requirements.txtを作成し、以下を記述します。
stable-video-diffusion/requirements.txt に以下を記載
diffusers
transformers
accelerate
torch
torchvision
safetensors
imageio[ffmpeg]requirements.txt に必要なライブラリがリストアップされているので、以下のコマンドでインストールできます。
pip install -r requirements.txtもし requirements.txt がない場合、以下のコマンドを手動で実行してください。
pip install diffusers transformers accelerate scipy numpy2-4. スクリプトを実行
動画生成スクリプト generate_video.py を実行します。
python generate_video.py実行すると、以下のように進捗が表示されます。

1 フレームごとに処理が進み、全フレームの処理が完了すると、動画ファイルが生成されます。
処理を止めるには Ctrl + C または タスクマネージャーで Python を終了
2-5. 実行中の GPU 使用率確認
GPU の使用率を確認するには、nvidia-smi コマンドを実行します。
cd C:\Program Files\NVIDIA Corporation\NVSMI
nvidia-smi実行結果の例:
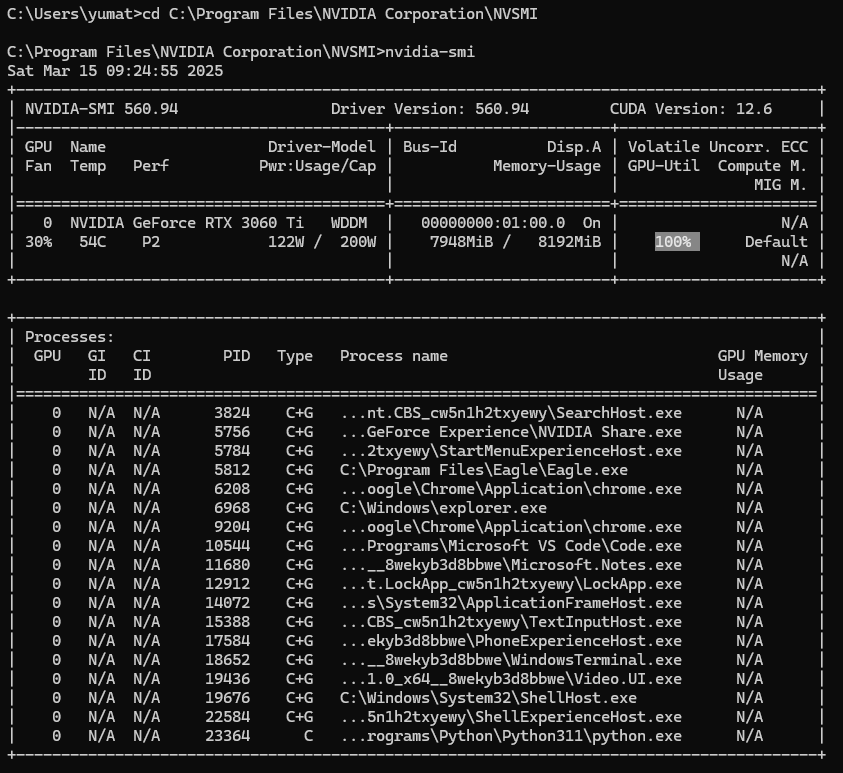
GPU 使用率が 100% になっている場合、動画生成に GPU がフル活用されていることを意味します。
2-6. 動画生成を高速化する方法
--fp16 オプションを使う
Stable Diffusion の動画生成スクリプトに --fp16 を追加すると、半精度(FP16)計算 に切り替わり、処理が軽くなります。
python generate_video.py --fp16RTX 3060 Ti は FP16 に対応しているため、VRAM使用量を削減し、処理速度を向上 させることができます。
xformersを有効化
xformers は メモリ使用効率を改善するライブラリ です。 以下のコマンドでインストール可能:
pip install xformersスクリプト実行時に --xformers を追加:
python generate_video.py --xformersこれにより、特にVRAMの消費が抑えられ、処理が速くなります。
解像度を下げる
スクリプト内の設定で 解像度(width, height)を小さくする と、計算量が減り速度が向上します。
steps(推論回数)を減らす
デフォルトでは steps=50 などになっている可能性があるため、例えば steps=25 に減らすと高速化できます。
実行中の処理を解説
1回目の実行
1回目の generate_video.py 実行時には、モデルのダウンロードや環境構築が必要となるため、処理が比較的時間がかかります。
- 設定ファイルのロード
- スクリプトの実行に必要な設定値を読み込む。
- モデルのダウンロード(初回のみ)
diffusion_pytorch_model.safetensorsなどの重みデータをダウンロード。- 初回実行時のみ必要。
- モデルのロード
- ダウンロードしたモデルをメモリに読み込む。
- 入力データの処理
- テキストや画像をエンコードし、モデルが扱いやすい形式に変換。
- 画像・動画フレームの生成
- Diffusion Model を実行し、生成を行う。
- 動画の作成
- 生成されたフレームを
ffmpegなどで結合し、動画ファイルを作成。
- 生成されたフレームを
- 出力の保存
- 完成した動画を指定フォルダに保存。
2回目以降の実行
2回目以降は、初回にダウンロードしたモデルや設定を再利用できるため、処理が高速化されます。
- 設定ファイルのロード
- 1回目と同様に設定ファイルを読み込む。
- モデルのロード(キャッシュから)
- 既にダウンロード済みの
safetensorsをローカルから読み込み、メモリに展開。
- 既にダウンロード済みの
- 入力データの処理
- 新しいテキストや画像をエンコード。
- 画像・動画フレームの生成
- Diffusion Model を用いて画像を生成。
- 動画の作成
ffmpegで結合し、動画を作成。
- 出力の保存
- 指定フォルダに動画ファイルを保存。
2回目以降の高速化ポイント
- モデルのダウンロードが不要
- 処理速度が向上(特にGPU使用時)
- 乱数シードを固定しない場合、異なる動画が生成可能
- 異なるプロンプト(テキスト)を入力すれば、新しい動画を作成可能
さらに高速化する方法として、
- モデルの事前ロード(スクリプトの常駐化)
- 中間キャッシュの活用(生成画像を再利用)
- FP16(半精度演算)を用いた計算最適化 などが考えられます。
まとめ
本記事では、Stable Video Diffusion をローカル環境で実行する方法 を解説しました。
手順のおさらい
- 事前準備(Hugging Face のトークン取得、PyTorch の CUDA 対応版インストール)
- ディレクトリ構成の準備
- スクリプトの実行
- GPU 使用率の確認
Stable Video Diffusion をローカルで動作させることで、無料で無制限に動画を生成 できます。ただし、動画の品質や解像度によっては処理時間が長くなる ため、GPU の性能を考慮しながら調整すると良いでしょう!
興味のある方は、さらに高品質な動画生成に挑戦してみてください! 🚀